


[Meta] Surveillance and Control

Why a contextual level of privacy may be required to protect inhabitants from some of the more alarming aspects of metaverse manipulation and the erosion of autonomy (experience machines, reality distortion and AI and dataism) and how new tech can exacerbate the existing problem or be part of the solution.

This is part 4 in a series of essays about the metaverse, please go back to the enjoyment guide or the overall index to explore further.
Index:
LEVEL 1: RECRUIT
Introduction: the state of privacy
The Perceptions of Privacy: are all privacy advocates hobgoblins?
The Value of Privacy: is privacy intrinsically valuable?
Contextual and Consensual Privacy: is privacy equally important all the time?
Mini-Recap: whatyatalkinabeet?
Corporate Surveillance and Manipulation: is surveillance a healthy business model?
State Surveillance and Overreach: why do nation-states like surveillance?
LEVEL 2: HARDENED
Shadow Games: who the churches and scribes now?
[Meta]control and Futureproofing: how does this all change in the metaverse?
LEVEL 3: VETERAN
Tweaking Humanism: can humans be hacked?
Echo Chambers → Experience Machines: how will the scope for personalisation evolve?
Information Distortion → Reality Distortion: what’s/who’s da truth?
Network Design: a transition from scale to quality of relatedness?
AI and Dataism: is free will a meme?
The Realignment: is the age of men over?
Phygital Algorithmic Governance: is the meatspace age of men over
Censorship and Control: is the excessive usurpation of internal moral autonomy sensible?
Money & Censorship: can money be used to undermine autonomy?
Reputation Systems & Privacy: another way to combat hobgoblins?
Cautious and Contextual Reputation: what does this middle ground look like?
Onchain Transparency and Pseudonymity: surveillance conducive?
Free-Market Autonomy: how much does autonomy cost?
Threading the Needle: where forth art though pragmatic solution?
An Autonomy-Focused Solution: this is the way?
Introduction:
Regarding the metaverse and surveillance and control, whilst we undoubtedly want to connect with others to achieve relatedness, different approaches can be detrimental to autonomy. Existing structures and business models in the closed metaverse seek to undermine that autonomy and, through several externalities (tweaking humanism, AI and dataism, and censorship and manipulation), will result in unfulfilling landscapes. Privacy is thus an essential part of the toolkit to achieve the autonomous agent; by leveraging primitives as part of the open metaverse ethos, autonomy may be preserved, organic relatedness may ensue, and subsequent fulfilment achieved.

As to why now, the granularity of digital information and the subsequent scale of surveillance is growing, whereas implementations of privacy are becoming increasingly redundant. Unprecedented mass surveillance culture arguably started in the 70s, followed by radomes in the 80s, and became accepted and pushed under the rug in the 10s. Since then, it has evolved into an even more vastly invasive and hard-to-quantify landscape. In short, practices have increased, and the legal protections or barriers to privacy have not.
NB: Whilst there are several types, sousveillance, metaveillance, dataveillance, etc., surveillance will be used as a catch-all unless specifically stated.
In the metaverse and its convergences with legacy systems, the individual will be subject to heightened surveillance and subsequent manipulation from various avenues and machinery. Therefore, sufficient, optional, and customisable privacy will be required to facilitate those convergences and a favourable exchange of information to create dynamic and fulfilling worlds. But before we get to how the current state of affairs will be much more alarming in the metaverse, some general background may be helpful.
“A system is nothing more than the subordination of all aspects of the universe to any one of such aspects.” - Borges.
Surveillance subordinates the privacy of some to protect the rights of others on a spectrum from care to control. Simplistic conceptions of surveillance are either positive (necessary social control) or negative (constraining free will), with a delicate balance between the two seemingly optimal.
In the past, attempts to thread the needle between privacy and surveillance in rights-preserving bills such as the Fourth Amendment were written with limited room for technological advancement. Today, those same bills are less effective as incursions come from many angles, and subsequent outrage is parried with examples of modern-day McCarthyism, leveraging fear for compliance.
“The whole aim of practical politics is to keep the populace alarmed (and hence clamorous to be led to safety) by menacing it with an endless series of hobgoblins, all of them imaginary.” - Mencken.
NB: The term hobgoblins will be used throughout as a catchall for nefarious actors.
Whilst some hobgoblins are undoubtedly real and their activities impactful and dishonourable, their symbolic use leverages primal risk aversion to elicit disproportionate apprehension (panic > reason).
Ideally, surveillance should prevent more exploitation of its citizens than it enables. This should still be the mission aim, but it is becoming increasingly unclear if the risks (and costs) that supposedly justify the enhanced current state of surveillance are justified. Conversely, the value of privacy has never been more in question.
Legally, whilst the ‘right’ to privacy is limited in the US, found in the penumbras, and more fundamental in the EU, they are often hard to enforce and rarely enjoy the same level of strict scrutiny, meaning that an infringement must be sufficiently narrow and in the states interest to be granted, as other fundamental rights.
Socially, many sense their privacy is not respected but feel at a loss of how to do anything. A lack of privacy has become viewed as more of a ‘nothing to hide’ dismissal to most, a nuisance to some, and a good precaution for criminals for advocates.
The defence of privacy has also become inherently taboo; those who do so are assumed guilty of actual or intentional hobgoblinery - seeking the shield to use the sword rather than the shield itself. There are those in the ‘nothing to hide’ camp, the short-termist non-call-to-arms for those who see nothing amiss with a loss of privacy, a straightforward position to adopt yet a precarious one to defend. Whereas there are advocates of the opposite, using privacy as the shield from a more worrying sword.
To establish a common ground, let’s have a look at these perceptions.
The Perceptions of Privacy:
Are all privacy advocates hobgoblins?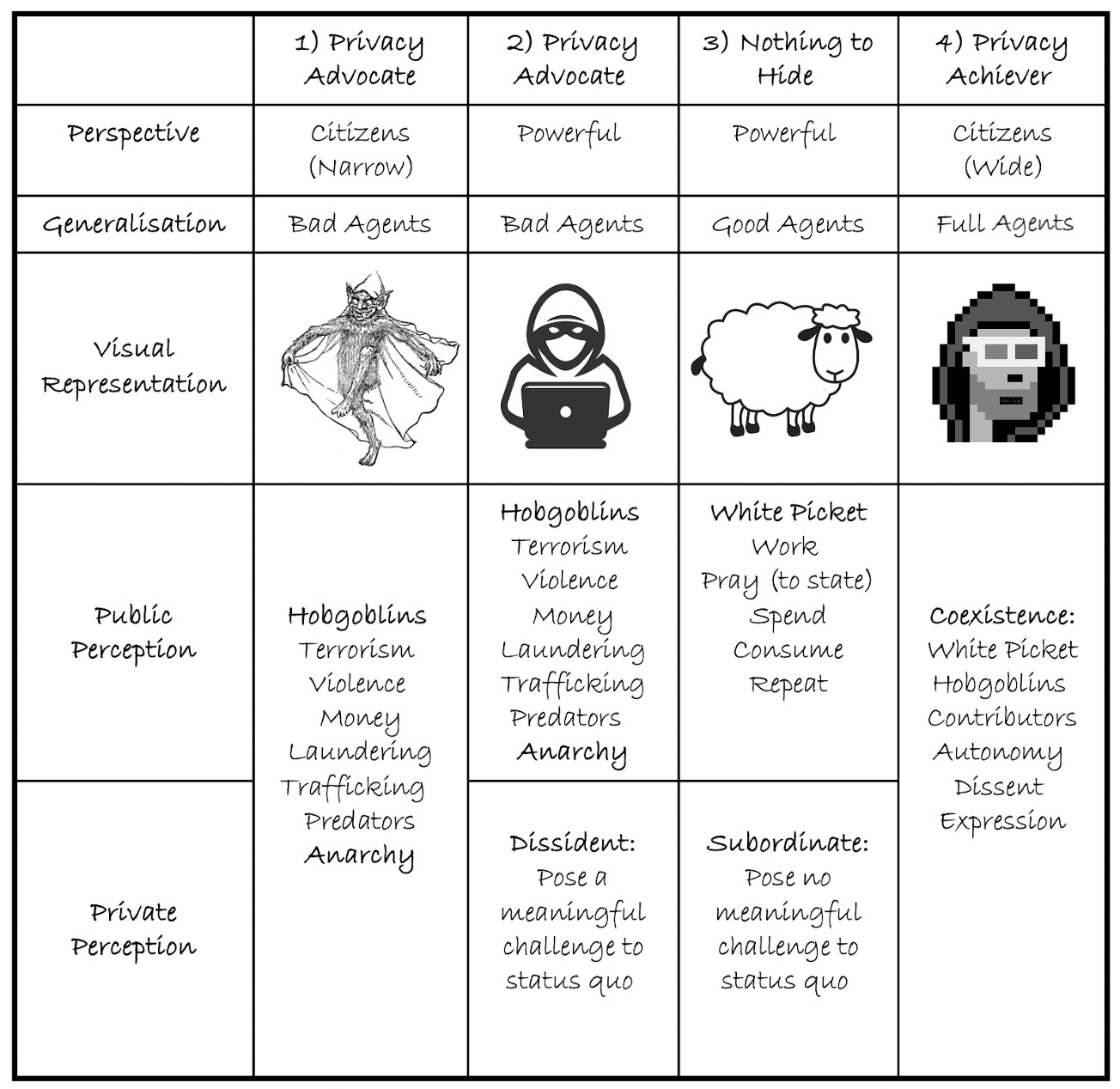
A huge barrier to change is that the activities of the bad agents overshadow the legitimate interests of the full agents and so they are bundled into one stigmatised bucket.
There are differences in perception (and separation between public and private narratives) between citizens and those in power over why people seek privacy. Citizens who use this argument tend to have narrow and usually negative definitions of privacy advocates. These bad agents (hobgoblins) are usually perceived to engage exclusively in illegal activities (Advocate 1). Whereas some in power, alongside the hobgoblins (public narrative), privately believe privacy seekers are bad agents because they pose a meaningful threat to aggregated power and aims of control (Advocate 2, Private Perception), as those who seek monopolies on authority have incentives to remove privacy, as it gives alternative power to whomever it is afforded.
Then, there is the third type of agent, the subordinate, with nothing to hide (Advocate 3). This non-advocate has become so unthreatening to any convergence of power that they can hide in plain sight. They may engage in white picket activities with reduced fear and increased protection from hobgoblins. However, in the longer term, meek compliance with stasis is one in which various liberties are eventually eroded, as those on the other side of the social contract will only seek more power without sufficient checks and balances. Additionally, this becomes more one-sided over time; one might want to engage in relatively unimpeded decisions or reasonable dissent in the future or for others to express their dissent on their behalf. A pluralistic society should cater to all aspects, not just where the status quo is furthered.
TLDR: to protect the livestock, it is easier to give them all a shield rather than hunt down all the hobgoblins, as you will run into fewer dilemmas… i.e., agreeing on a universal definition for a hobgoblin. To understand why the optimal balance should be the privacy achiever (advocate 4), one must understand the benefits of privacy to achieve autonomy and the beneficial second-order effects.
The Value of Privacy:
Is privacy intrinsically valuable?
The optimal system defends against the minority of hobgoblins whilst ensuring that the remaining good actors are not subjugated to overly livestockeseque compliance and excessive surveillance, leading to vectors for manipulation and coercion. As the metaverse will encompass both the digital and the physical realms, implications across both should be considered to ascertain the value of privacy to achieve the autonomous agent.
To partially understand the value of privacy, one can look to more traditional advocates (pre-mass digital surveillance) who discuss more physical components. Kant regards privacy as an inherent necessity for autonomy and moral agency; Mill as a predicate for happiness, individuality, and diversity; Foucault as a tool to resist the eventual pervasive conformities of modern society, universal prison culture and dignity preservation; and Warren & Brandeis to ensure the right to be left alone, suggesting that individuals have a fundamental right to prevent invasions into their private lives to ensure various freedoms (or negative liberty).
Without privacy to level the playing field, individuals within a system can be more vulnerable to powerful and unethical actors (especially those in less liberal environments) attempting to undermine autonomy.
An adjacent case for privacy can be found through abstract value propositions of human entropy or nature. Despite sufficient literature, it is not definitively capturable by any single word, so a definition of valuable human entropy can be aggregated from various others. (1) Qualia: underlying human value outside full comprehension. Emphasised by Nagel's subjectivity of consciousness, Lewis's fallibilism and conceptual pragmatism, and Jackson's physically elusive epiphenomenal qualia. (2) Élan vital: Bergson's urge for spontaneity, vital force, or creative impulse. (3) Essence: the unique qualities distinguishing humans from machines (so far) and other sentient beings, encompassing agency, consciousness, and emotion. Emphasised by Heidegger's "Dasein" of relatability and extended authenticity, Searle's unique conscious experience, and Dreyfus's intuition and contextual understanding.
Combined with the Epicurean concept of ataraxia (an ideal state defined by tranquillity or the absence of distress or mental disturbance), a key component of purely non-physical pleasure, is perhaps the closest term to a catch-all in the non-physical.
All charmingly position the relatively unexplainable importance of some form of free will, but it's a pretty wide net. What does privacy give us?
Privacy is instrumentally valuable as a shield to protect other rights.Despite the ranging literature, the common denominator throughout the traditional and the abstract is that privacy is instrumentally valuable as a shield against undue manipulation and coercion that seeks to undermine autonomy in various forms. As such, the link between privacy and autonomy in the digital realm encompasses many internal and external characteristics, although not mutually exclusive.
Internally, people should have the option to be left to their own devices to find an optimal balance between desire and virtue and therefore develop a subjection to an internal moral law as opposed to heteronomy (outside of natural desire).
This allows individuals to live in harmony with others and self-regulate through cooperative rational interactions.
When individuals think they are being watched, inhibitions are suppressed and self-censored, increasing suspicion and eroding societal trust. Additionally, surveillance creates subtle mental limitations (more effective than overt counterparts). It is not just the process of being watched; the knowledge that being watched is possible also produces fear and self-censorship (subtle Orwellian telescreens etc.).
Privacy creates a realm where people can reason and think without undue surveillance, where creativity, exploration, and dissent (both healthy and unhealthy) reside.
Externally, as outlined by a subset of Self-Determination Theory (SDT), more active forms of autonomy, such as the ability to achieve self-actualisation through a feeling of causal agency and the ability to make decisions. Again, this is not independent of the will of others but an overall feeling of freedom (positive expression).
Again, finding a modern catch-all term to define the type of autonomy at stake without sufficient privacy is challenging, as many different areas are at risk. We will focus on both internal and external aspects, such as the freedom to think (maintenance of relatively uninhibited reason), to act (make relatively unimpeded decisions), and to interact (avoidance of excessive censorship). To encapsulate the above, autonomy will be used as an umbrella term to cover what privacy can instrumentally preserve and its value proposition. However, more specific underlying forms of freedom will be highlighted where relevant.
Contextual and Consensual Privacy:
Is privacy equally important all the time? “Privacy is necessary for an open society in the electronic age. Privacy is not secrecy. A private matter is something one doesn't want the whole world to know, but a secret matter is something one doesn't want anybody to know. Privacy is the power to selectively reveal oneself to the world.” - Hughes.

Privacy is not an absolute and limitless right; it likely should be impeded, broadly, when doing so prevents more harm to others than its incursion, as freedom likely ends where that of another begins. But, not at the unnecessary expense of internal or external autonomy to increase profit margins or to propagate asymmetric power accrual as the main aim.
Furthermore, this right does not extend exclusively across the extent to which one wants to influence others and is relative to the spaces in which invasions occur - i.e., not everyone wants to or can be left alone all the time. Privacy is also contextual across venues and taxonomies of information: collection, processing, dissemination, and invasion. As such, it is often difficult to segregate where a breach of privacy is acceptable. So how to decide?
Consent is also contextual and has many different types; generally, it ensures that people agree with the intentions of others. The more it is sought, the surer the agreement. In a privacy context, consent is a bulwark against invasion, adjudicating excess whilst entailing compliance. However, in the digital age, consent has recently become more of an afterthought (for an overview, see Cohen or Nissenbaum).
Modern day requerimientos? Ideally, ramifications are understood, and subsequent consent is given in relevant contexts. This is typically called voluntary consent, where there is full disclosure and capacity to understand the implications of relevant information when access is given to data. In most of the digital landscape thus far, obtaining consent has either a) been rendered obsolete through laws that make information accessible by default (to certain parties) or b) obtained in a subversive manner through either coerced consent (given little alternative, i.e., no access) or deceived consent (without full capacity/understanding or legal representation). Furthermore, there are various ways in which the requirement for consent can be avoided or rendered ineffective through various means:

Legitimate interest (for commercial benefit).
Dark patterns (pre-ticked checkboxes and positioning, etc.)
Initial opt-out models.
Evasive consent language.
Bundled initial consent.
Superseding legal bases.
Vital interest.
Public task.
Extremely lengthy t’s and c’s.
As such, privacy choices afforded by many corporations have become involuntary due to leveraged cognitive biases and human limitations. In addition, states have passed increasingly significant laws that circumvent the consent requirement for personal data, making access default.
Mini-Recap:
Wadiyatalkinabeet?
It is almost common knowledge that everything you search, say, write, think and do using or near a digital device can be recorded, aggregated, analysed, and scrutinised; the actions taken after that are where it begins to get worrisome.
Ideally, and in relatively recent history, states and corporations have had to earn the right to surveil or access citizen data; the presumption of innocence as a legal principle uttered all the way back when by Prudentissimus. Laws were made to balance civil liberties against the merits of reasonable suspicion, probable cause and relevant warrants in specific instances to ensure a bubble of freedom that citizens may use to exercise those rights.
This is currently not the status quo in the digital realm and requires correction if the metaverse is to exist on a plane that is enjoyable or fit for habitation.
There are plenty of shades of grey between right and wrong. These hard-to-quantify grey areas are those that privacy helps to preserve, where the moral and ethical ambiguity resides and always will.
Wtf has this got to do with the metaverse? For this section, readers must expand their view of the metaverse to the intersection of all digital, analogue and radio-related technologies that are surveilled, ingested and analysed in every sphere of life.
While it may sound so, unfortunately, it's not science fiction; this is happening right now, and there has never been this level of surveillance.
Where’s the problem? Users face several intertwined vectors of surveillance in the digital realm.
Firstly, from corporations (primarily for financial gain). Secondly, from states (slightly more coercive control). Thirdly, from autonomous entities (acting on whose intentions are as yet unknown). Finally, from each other.
This is not to say that everyone will be alarmed by the current lack of digital privacy; conversely, many think it is necessary and an inevitable trajectory. But it is hard to win the argument that the noose isn't tightening over time nor that the surface area for digital surveillance isn't increasing. You only have to accept that the future state of surveillance and subsequent manipulation is concerning without privacy as future-proofing.
Hopefully, this is the dark age of digital transformation, and people will one day look back in disbelief at what was happening, but just in case this isn't inevitable, privacy can act as a shield.
Before we get to the juicy bits and the potential remedies, let's meet some of our surveillants (if you’d rather level straight up, please head to [meta]control).
Corporate Surveillance and Manipulation:
Is one-sided surveillance a healthy business model? “There are only two industries that refer to customers as 'users', one is IT, the other is the illegal drugs trade.” - Edward Tufte.

Surveillance capitalism (SC) describes the process whereby corporations collect consumer data to create products that facilitate prediction. Once collected, these products/data are then either used or sold on the behavioural futures market to entities who initially wanted to understand and/or subsequently influence the behaviour of any user.
Three factors have generally made this possible:
A need for personalised products to cater to a sense of unique self-conception.
A rise of free-market neoliberalism leading to decreased state interference in private enterprise.
Post 9/11 attitude of surveillance exceptionalism to maintain and widen national security nets and data collection. Allowing both state-led and private enterprises (better placed) to ramp up surveillance culture.
Initially, the power dynamics were more balanced; SC was centred around catering to predictions of wants. If these products could predict what consumers wanted faster than they knew it, they would fetch better prices at auction. At this point, competition between entities has concerned the quantities of data that can be extracted and the damage to the user is mostly infringements on privacy.
But predictions (although exponentially more accurate) still leave room for errors and, in this economy, may result in unrealised gains, predicating the need for some form of influence. Actuation requires ubiquitous action where firms aim to change one’s choices and behaviours to increase the performance of predictive products and increase revenue; it consists of several behavioural modification strategies.
This is where autonomy is actively undermined through various subtle, historically perfected processes:
Tuning - utilising subliminal messages or nudges designed to elicit specific engagement or behaviours.
Herding - controlling elements of an environment to encourage groups of people towards a specific outcome.
Conditioning - action chain where stimuli initiate desired behaviour, and then said behaviour is reinforced through rewards to enshrine patterns.
One of the more common suggestions is that data gets harvested and sold to the highest bidder; it's more of a race to design the best proprietary model for influence using aggregated metadata and linkability to ascertain the target.
Further enhanced through commonly used behavioural modification strategies: addictive recommendation systems, gamification, comparison, dark patterns, emotional contagion, variable rewards, hypernudging, location-based influence, echo chambers, and social proof (all being explored, exploited and expanded).
Still, the existential threats can be hard to see.
What's the big deal? These platforms cannot (yet) make people mindless zombies, but they have statistically meaningful impacts, especially around the fringe. But the societal severity of behavioural modification depends on the context of the nudge, i.e., less serious about buying a product and more about voting on your next president. Nonetheless, the infringements on autonomy are equal in both.
Suppose the abstract erosion of internal and external autonomy is not convincing. In that case, the subtle influence of political events in Myanmar, the UK, the US, France, Germany and Turkey might be more compelling.
But some are still loath to concede the impact of surveillance capitalism and behavioural modification, but it is hard to deny that it is possible and that it’s not escalating. Even if you are not concerned just yet, then the argument must be made from a futureproofing standpoint. As will be explored later, as the metaverse grows, so does the scope for influence.
Is it all bad? A common phrase is associated with these corporate issues - 'if you are not paying for the product, then you are the product'.
Whilst generally true, the picture painted of innocent lambs being led to slaughter might be exaggerated as this platform-user interaction is partially mutually beneficial; users exchange their data for a variety of free and accessible services based on a privacy calculus where the benefits of disclosure are weighed against infringements on privacy.
Disclosure, although realistically non-consensual, has thus far usually won out.
Despite such benefits, the corporate use of data to subversively influence the behaviour of individuals is not conducive to creativity nor autonomy and leads to various effects (discussed later) on the autonomous agent. Moreover, the nature of the privacy calculus can change when different business models (users → stakeholders) make the choice less binary.
Are corporations evil? Firing moralistic criticisms at corporations for not handling these arising externalities is low-hanging fruit. With the scale achieved, they now have to deal with problems that nation-states were supposed to address (privacy vs. beneficial data collection, censorship vs. free speech, and truth vs. misinformation).
These structures just want to make money and, as such, are best placed to balance investors' needs and their management over overall well-being (stakeholders > users). In most cases, jawboning (state-paid surveillance assistance), ease of surveillance, and censorship are responsibilities most would rather be rid of with a return to probable cause = breach of privacy likely favoured. As such, alternative frameworks are likely better placed.
You might still be thinking, what is this panic merchant talking about? I'm content with my current trade of free services for subtle manipulation and exchange of data, but this is not the end state of manipulation (transition to hypermanipulation). If the business model of manipulation for profit is extended into the metaverse and privacy is not implemented sufficiently, things will get much worse.
State Surveillance and Overreach:
Why do nation-states like surveillance? “Surveillance is understood as any focused attention to personal details for the purposes of influence, management, or control.” - Lyon.

Nation-states will inevitably want access to data from the metaverse to continue the norm of their surveillance expansion into an incredibly data-rich environment where citizens will spend increasing amounts of their time. As such, the balance between privacy and compliance with legacy societies must be carefully implemented, as these systems will collide frequently.
Whilst extremely persuasive abuses of power (also arguably coercive) using methods of tuning, herding, and conditioning by corporations may make more sparkling headlines, there is something potentially more unsettling about the increase in digital state surveillance.
There are 18 visible intelligence agencies in the US, most mandated to protect their citizens against exploitation. Some are tasked with domestic surveillance and others with protecting the population from national threats, but due to natural ambition, all compete to improve their influence and funding.
This includes collecting and using more and more data to meet these ends; the party line is that these organisations are for observation, not manipulation, but intervention is increasingly common (below), and thus, the noose continues to tighten.
There is a wealth of evidence and (tenuous) legal justification for these practices.
Many acronyms and codenames have given glimpses into what has been done thus far (XKeyscore, Tempora, PRISM, and Stellar Wind). Similarly, legal justifications in the US, for example, include the USA Patriot Act (remove most things), FISA (foreign data), CALEA (comms), Executive Orders 12333, 13355, then 13470 (NSA foundation) and more, CISA (including liability protection on personal data sharing) and Presidential Policy Directive 20.
Whilst this legislation is not uncontentious, and some provisions have been made that slightly curb previous acts, e.g., the USA Freedom Act (limiting the Patriot Act), the general trend has been towards noose-tightening, and, at this point, it's extremely unclear if the same strict scrutiny that these laws were subjected to when they were enacted would still stand up for many of these blanket provisions.
State and corporate surveillance are also intertwined.
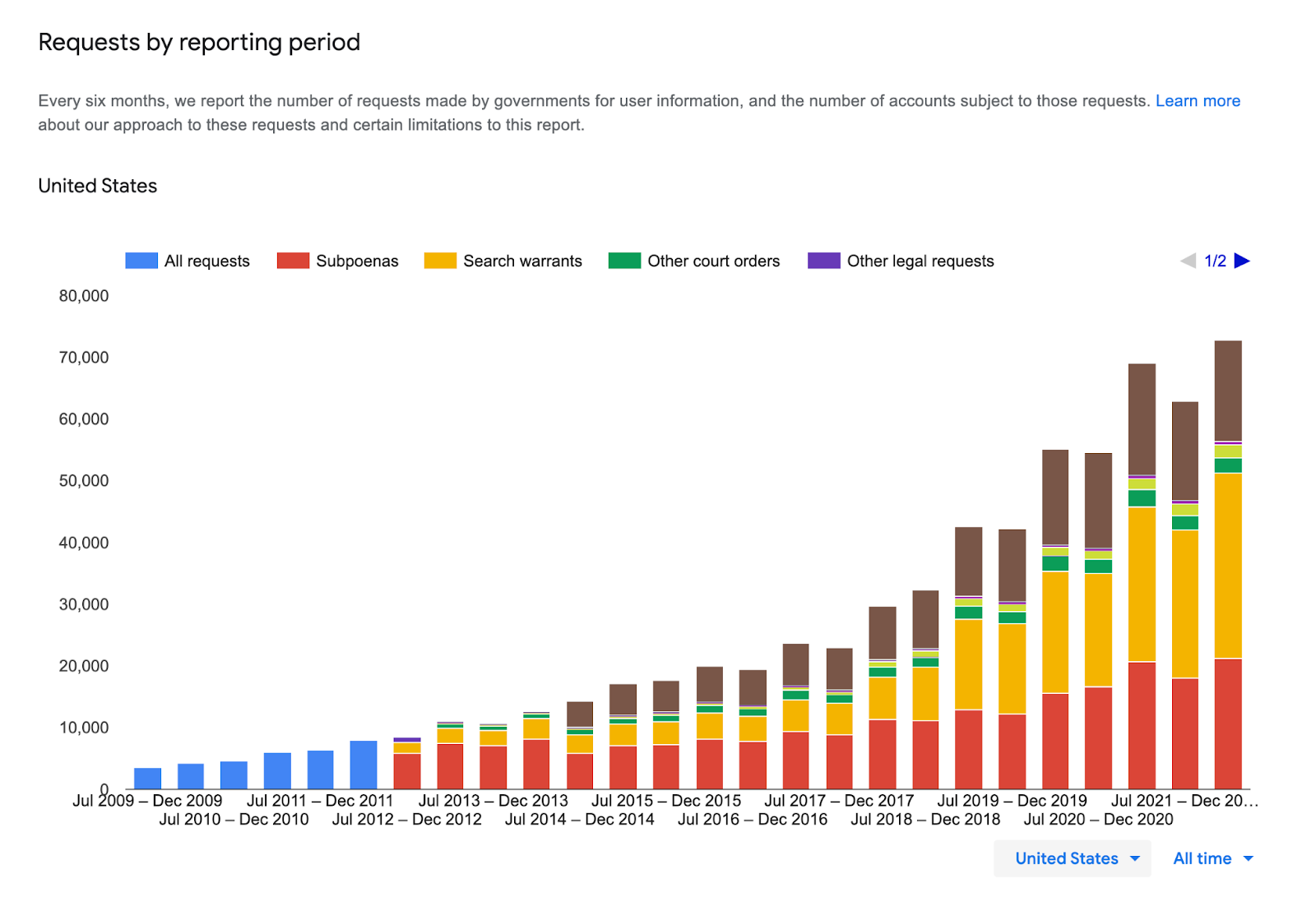
Cooperation (referred to as jawboning throughout) between states and corporations is increasingly routine, with an 83% average success rate over the last five years. Due to the overlap of state and corporate surveillance (Voyager), a grey area exists in what data can be used to inform and evidence state control. However, pushback still remains in some areas.
Most clauses will say they do not usually share data unless it is in response to law enforcement requests, mostly accompanied by subversive gag orders, so the user has no chance to protest.
If easy compliance is not forthcoming, various ‘legal’ requests can be used, such as geofence warrants & cell tower dumps, keyword search warrants and a range of subpoenas; if all else fails, they can just buy the data. Legacy legal systems have a tough time defending privacy with antiquated laws.
Furthermore, the requests are often broader than necessary, placing innocent bystanders under unnecessary scrutiny and resulting in all kinds of bycatch and increasingly hard-to-justify costs.
Is it all bad?Reactions of state overreach into supposedly personal data receive mixed reactions from the public depending on the nature of the intent and perpetrators of the alleged crime.
The scale of the FBI’s recent geofence warrant concerning Capitol Hill protests secured geolocation data from Google and call logs from mobile network providers was unprecedented. Despite securing several arrests, it meant that the data of approx. 5000 was scrutinised unnecessarily… some may argue that violent protestors deserve surveilling as it constitutes probable cause.
Is this even about constituent safety any more? But should data also be collected from unsuspecting women whilst using their period-tracking apps? Should companies such as Flo be subpoenaed for convictions? What about those outside the US whose surveillance needs even less permission or justification?
More importantly, will the people (and regulators) who dislike geolocation, period tracking or foreign spying agree on which one is right?
The consequences and contextual excuses for privacy invasions are only getting more far-fetched in a game of he/she/they did → justify:
“First they came for the
socialistsfinancial data and I did not speak out—because I was not a money launderer.Then they came for the
trade unionistslocation data, and I did not speak out—because I was not a protestor.Then they came for the
Jewsmenstruation apps, and I did not speak out—because I don’t get periods.Then they came for me—and there was no one left to speak for me.”
- Martin Niemöller
Often, precedents are set, and views are argued in inflammatory edge cases. A commitment to base-layer levels of increased privacy requires many contextual differences to be sidelined.
Whilst physical safety (OG public good) can be enhanced by these practices, removing the necessity for defending oneself or property with pitchforks, the incursion of state surveillance in the modern age often surpasses the fine line between maintaining order and excessive surveillance and controls on freedom.
Is this new? Suppression of the dissemination of information is not new; in regards to the printing press, there were attempts of suppression from church, corporations and state, the latter by the death penalty. Similarly, end-to-end encryption is being put in the crosshairs, one of the (current) final defences against data overreach.
Excess surveillance from the ruling elite to control the masses is also not new, in the Middle Ages any ideas of change were extinguished quickly, and surveillance was carried out by various spy and local informant systems (peer-to-peer communication was mostly verbal until the printing press) with little to no privacy in physical spaces.
Whatever gaps existed in the citizens' thoughts were filled with the ultimate surveillance (a stringent belief in an omniscient and omnipotent whitebeard). Furthermore, supposedly sacred and confidential confessions in the church were sometimes used as evidence of heresy, sacrilege and treason.

Due to the granular and relatively available nature of digital data versus physical, modern digital surveillance is far more effective, wide-ranging and colourful.
Are states evil? Depends on your definition of evil but they certainly can be. Every dictatorship in history has sought to increase the scope for one-sided information gathering about their citizens, and we have never had this level before. However, we know from experience that blind trust is not the way, and safeguards are needed just in case.
You might still be thinking, what is this tinfoil hat dude talking about? I'm content with my current trade of (dubious) hobgoblin minimisation for subversively losing the right and ability to exercise various liberties.
Excess state surveillance can lead to various not-so-great things: discrimination, chilling effects on dissent and expression, abuses of power, stifled creativity and the inhibition of the free exchange of ideas.
But surveillance states are only for autocratic regimes... right?
It is scary to admit that something is wrong because it's historically uncharted territory. But when you remember the (currently) inescapable reality that everyone to a certain extent knows 1) everything you search, say, write, think and do using a digital device is recorded, analysed, aggregated, and scrutinised, 2) the full extent of surveillance or negative societal impact is yet to be realised, 3) the benefit of these practices is yet to be justified... does that sound like a good idea?
When people discuss privacy, they are more often than not referring to a right to freedom, and if the general adage that privacy is dead is true, then what remains of freedom?
If Western liberal democracies are only as strong as their constituent citizens, then it is becoming clear that they need privacy protections in the age of surveillance. The rule of law and the allowance of criminal investigations that invade privacy were supposed to be hard for a reason and the assumption of innocence over guilt and probable cause has served as best as it can up until now. Is there a justification to change that now just because we can?
The trend in surveillance and subsequent overreach is only getting worse. If privacy is not retrofitted now, things could get much more concerning, as will be explored.
RECRUIT → HARDENED

Shadow Games, Platforms as the Church and Coders as Scribal Class:
Who the Church and scribes now?
There are parallels and differences between corporations' and states' monopolies on information, privacy and power and the one the church and state had in the Middle Ages. Historically, it was overt, whereas today, it is more covert.
Regarding privacy, Middle Ages life was conducted in tight-knit communities where affairs were often public but limited. In contrast, the modern era created an interconnected and ubiquitous landscape for publicity, unlimited and with more scope for infringement.
In terms of information, not all of it is as easily guarded as in the Middle Ages. There is a comprehensive, beneficial and visible layer of data accessible to most users. But there is also a large hidden 'shadow realm' of derivative and private knowledge, partially composed of the surplus behavioural data, residing in proprietary domains alongside the secret modus operandi of such practices.
In terms of power, this asymmetric power shift is, again, employed subversively. Even if one were to gain access (through arduous and likely unsuccessful legal action), it would be written in the modern-day version of the scribal class Latin, programming languages - challenging to decode and understand for the technical layman. The imbalance can also be viewed through the lens of privacy; states and corporations (aside from some thorough investigative journalism or whistleblowing) have comparatively more privacy regarding their operations than regular citizens do of theirs.
For individuals to escape this one-sided shift, there may either be an increase in transparency from the shadow realm (unlikely) or an increase in privacy on the user side (required).
[Meta]control and Futureproofing:
How does this all change in the metaverse? It is unlikely (or impossible) that the level of surveillance and general abuse of coercive and persuasive power in the metaverse without sufficient privacy will not increase, given the level of trust required in the platform not to do so and the historical abuse and state cooperation over personal data.
There will be an exponentially increased surface area for data collection in any of the conceptions, as mentioned earlier, of how it will practically unfold; more time spent in persistent, synchronous, interoperable spaces with fully functioning economies that may be more immersive through technologies such as VR/AR/MR (above) spanning both physical and digital environments - these will leave obvious data trails.
Therefore, the principles behind the metaverse design are essential to how the data will or will not be used.
The current privacy and data laws, designed for the physical world and already a stretch for the existing internet layer, will be almost defunct in the metaverse. Furthermore, physical integration in the metaverse through hardware/software will require more technical privacy protections (below).
Excessive user privacy from corporations is unlikely in any closed virtual world, as it goes against the standard monetisation model and assimilation with state surveillance practices. Furthermore, it will be hard to achieve; exemplified by the ease of user identification, a recent study analysed simple motion data from the Beat Saber app (basic virtual environment) and was able to identify 94% of 50,000 unique users using 100 seconds of simple motion data.
The extent of the consequences of combining…
An unprecedented amount of personal data: biometrics (fingerprint, voice, facial, retinal, heartbeat, blood pressure), EEG brainwaves, financial transactions, comms, emotive responses and the level of separation between physical and digital identity.
A superior means to analyse and implement superior methods of prediction and control (AI).
…is as yet unknown, but we will have an extensive guess in the subsequent sections.
But as a quick and simple precursor, control theory is the ability to design and analyse systems using controllers and sensors to behave optimally (dictated by the controller or whoever controls the controller).
There are broadly two types: open or closed-loop system control, with feedback being the critical difference.

These principles can be applied to the metaverse. With greater feedback (surveillance) comes greater scope to control and influence the system.

Regarding the inhabitants, they have the potential to become active participants rather than voyeurs (shift from third to first person). As they become more present as part of the system and, thus, more influenceable.

Although immersive media will affect a sense of presence and be far more perceptually powerful and persuasive. In a closed metaverse (the ultimate sensor), due to increased granularity and traceability of the data, the inputs and outputs become more available in real-time and, with more use, compounded and stored. The user becomes subject to enhanced feedback control and control theory, becoming the system itself, influenceable by the controller (AI), and ultimately controlled by the system's owner. One's "process output" (both internal and external) becomes mouldable, and the "process variable" inevitably becomes less varied over time.
So, closed environments can be the perfect arena for ease of systems control, and manipulation through persuasive and coercive power.
TLDR: when data availability + scope for system control ↑ = autonomy ↓Aside from these general factors, several other and more specific externalities that exemplify systems control in practice should be considered.
The following sections: tweaking humanism, experience machines, reality distortion, network design, AI and dataism, the realignment, phygital algorithmic governance, censorship, and financial control, will outline and discuss the nuances of the externality in an open or closed environment and why adherence to the former option tends to mitigate the erosion of autonomy.
HARDENED → VETERAN

Tweaking Humanism:
Can humans be hacked? Mass influence is not new, but the accuracy and effectiveness of these systems are.
Programmatic influence enhanced by AI and design can be more subtle, manipulative, and directly correlated to data availability and other heuristics that determine success.
Although each of the following sections will have a different theme relating to various constructs in the metaverse…
Echo Chambers = experience
Information Distortion = truth
Network Design = technical choice
AI and Dataism = free will or probability
Realignment = access and intention
Phygital Algorithmic Governance = meatspace integrations
… they are all interconnected to varying degrees. Some will be more obviously AI-y or metaverse-y than others, but all are relatively medium agnostic. Despite this confusion, they all follow the same notion:
The metaverse will [currently] be more dangerous than it's worth.Echo Chambers → Experience Machines:
How will the scope for personalisation evolve? “[...] the technology will be so good it will be very hard for people to
watch or consume[experience] something that has not in some sense been tailored for them." - Eric Schmidt.
Combined with a more subscription-based news model where people tend to favour non-objective, positively reinforcing and emotive media, much information is now consumed on centralised social media platforms. The transition from the deterministic to probabilistic personalisation of content feeds and a combination of tailored content and adverts imbued with someone else's intentions has, unsurprisingly, not led to more organic fulfilment but rather an unnatural other-actualisation or channelled and exaggerated groupthink (misinformation aside).
There are disagreements about the exact level of customisation these algorithms can achieve; currently, individually personalised content is not delivered on demand to cater to each worldview. Instead, people with high coefficients on social graphs (based on similarity metrics) are herded together and served content that meets the preferences of the group(s) or the controllers (now experiencing social graph lock-in). These resulting echo chambers or 'rabbit holes' become sticky warrens filled with various comfortable reaffirmations of current worldviews that tend to increase conformity and illusions of objectivity (reading similar shades of the same argument). Furthermore, their programmed function to expand the time spent within these tunnels can sometimes increase effectiveness and polarisation (especially political).
NB: this polarisation can often become a barrier to effective solutions. If citizens can't hear each other, coordination is hampered as social pressures are diluted, and disruption is favoured over persuasion.
In the metaverse, advances in certain technologies (VR, AI procedural generation, BCIs, haptic feedback, and general computing) can enable a form of exaggerated erosion or experimentation with ‘meta echo-chambers', where experience machines become a possibility.
But they may not be as nice as they sound, depending on who controls that machine.
Herded news and banner ads → entire personalised worlds, scenarios, content and characters can be created in real-time, catering to any desire and framed in any world-view (respectable and sordid). Arguments on hedonism vs authenticity aside, these tailored experiences will exist (both above and below board), creating more extreme vectors for manipulation.
Without an optimal balance of privacy (user), consent (user), and transparency (modes of operation for collection and implementation), these scenarios could be subversively employed on a more automatic, invasive, impactful, exploitable and personalised spectrum leveraging more immersive media and enabling more effective influence, leading to a form of assisted self-censorship or exaggerated behavioural modification.
But these experience machines can only be as effective as the amount of data they have. If increased privacy decreases the flow of behavioural and personal data, these campaigns will be significantly less targeted and, thus, less effective in undermining autonomy.
Information Distortion → Reality Distortion:
What’s/who’s da truth? The “[...] the Age of Information has not yet become the Age of Understanding.” - Davidson & Rees Mogg.

Although the gusto for misinformation and memetic hobgoblinery is more of a human bug than a strictly commercial problem, the effects are worrying at scale. Unsurprisingly, in interconnected and global networks, this gusto becomes exacerbated.
Regarding autonomy, it's hard to make sound internal moral judgements or external decisions if the foundations of deliberation are questionable. Although this can be exaggerated in hierarchical networks (expanded on below), it can also occur in more peer-to-peer networks, albeit on a reduced scale and with sharper corrections.
Veracity in many scenarios is problematic as truth is a subjective and contextual commodity. Centralised ratings would be equally destructive, especially if economically motivated (general censorship is also addressed elsewhere).
It's generally incumbent on people to use information in the best way for them and evolve effective filtering systems. However, a distinction must be made between the adjudication of subjective truth (not helpful) and the more favourable disclosure of the origin of particular media (helpful).
Regarding more blatant fact-checking, the community can be beneficial.
NB: In recent events, (some) neutral-ish legacy institutions have still served as relatively reliable sources of information.
Regarding futureproofing for the metaverse, there is increased scope for misinformation due to the potential shift of media formats and data collection. Previously, the curtains of illusion were more user<AI>platform owner intentions, but now the content is not simply manipulated but created from scratch.
Instances such as…
synthetic media (creating scalable and effective mistrust)
autonomous AI agents leveraging accessible data (behavioural and biometric) to achieve various aims
tribal misinformation (e.g., QAnon → limitless speculative generative AI cults)
…can become increasingly convincing without limits to the means of influence or systems.

In terms of solutions, true accountability is crucial. Identifying agent ownership (‘not mine ser it did that on its own’) where possible and applicable (some will be more sovereign than others) will be essential to combat negative externalities.
Regarding privacy, this is a difficult needle to thread.
Excessive privacy (user-to-user) can facilitate the creation of malicious misinformation without social repercussions, and limited privacy (user-to-platform) can increase the effectiveness of shadow realm misinformation campaigns.
Open and decentralised cryptographic networks provide alternative paths, allowing for increased disclosures, verification of the origin and trajectory of information, data provenance, reputation systems and alternative system design (all discussed in more depth later). These can assist in combatting the velocity of misinformation, meaning that autonomy at least has some more grounding.
Network Design:
A transition from scale to quality of relatedness? “We are in great haste to construct a magnetic telegraph from Maine to Texas; but Maine and Texas, it may be, have nothing important to communicate…” Henry David Thoreau.

System design can have drastic effects on negative externalities and subsequent autonomy and relatedness.
Similarly to the strategic design of supermarkets, networks can be engineered to maximise the ease and effectiveness of influence. Below are several examples of the dominant designs in current social platforms:
Scale-Free Networks: where fewer nodes have a high number of connections.
Small-World Networks: easier to connect nodes in larger networks.
Preferential Attachment: reinforcing connections to popular nodes.
Hierarchical: organising nodes into layers of centralised power.
Community Detection: grouping like-mindedness.
Tipping Points: exaggerating the effects of small events.
Social Contagion: spreading mind viruses.
Threshold Models: influence collective behaviour.
These design choices can enhance the externalities described above, as well as the reinforcement of power, resistance to change, and suppression of dissent and creativity, as per reduced privacy and lack of consent of users facilitate the ease and effectiveness of these designs. In short, how you relate to people online is far more manipulated than in the physical world.
If performance (profit) is prioritised over ‘healthy’ system design, externalities will continue to be enhanced and exist where they otherwise might not.
In the current state of algorithmic organisation, a person with no sense of overly polarised opinion, some semblance of humility, and a balanced perspective may find it hard to gain popularity where they may have thrived in a meatspace forum. Case in point: a recent study suggests that political polarisation was reduced rather than amplified when participants were organised using an egalitarian network design.
Moving forward in social networks, there are alternative system designs, such as those using P2P (peer-to-peer), modular and decentralised system designs. There are various examples employing several alternatives, broadly grouped as DSNA (decentralised social networking architecture).

There will also be areas in which the algorithmic intermediation of relatedness varies. There will likely be cryptographically verified (partially using reputation discussed later) AI zoning in the metaverse:
Humans <> Humans (no AIs allowed).
Humans <> AIs (algorithmic governance and agents allowed on a spectrum).
AIs <> AIs (no humans allowed).
In certain virtual worlds, removing intermediaries as part of an open network design can have several benefits, including greater privacy, user optionality and general robustness. However, these systems may initially be quieter or comparatively boring as a byproduct (barring effective incentive systems and growing network effects).
Virtual worlds that remove substantial network activity may seem less fulfilling as a byproduct of natural content moderation and privacy (scale of relatedness). But ‘quietness’ does not mean less freedom of choice but freedom from excessive influence and a move towards fulfilling interactions (quality of relatedness). Users will still be able to connect to each other; however, increased privacy and consent will entail more customisable interactions based on preferences rather than profit (noise → signal).

Perhaps stretching Dunbar rings hasn't worked, and many connections were better made organically and not at scale. Current social platforms feel slightly overextended and flooded with misinformation, manipulation, and relatively irrelevant content; in the metaverse, there will be an optionality to transition to more traditional social networks in smaller, aligned and trusted enclaves.
Modern-day caravanserai, where the prohibition of violence, misinformation, and coercion can be slightly more programmatic and community-driven. Or at least middle-grounds will be optional.
AI and Dataism:
Is free will a meme? 
Another approach, broadly combining big data and life sciences, suggests that authority is transitioning from subjective humanism into more objective algorithms.
This is the supposed transition of Humanism (free will) → Dataism (probabilistic outcomes) and it goes something like this…
Organisms are biological algorithms, and feelings are not supernatural but probabilities shaped by natural selection to make good decisions. Until now, this has been a bit far-fetched as no one had enough data or the ability to analyse it effectively.
But combining aggregate knowledge of the body and brain and data collection (infotech = biotech) with the exponential rise in computing power and AI could make the probabilities much more accurate. It's already happening in medicine, but the implications will depend on legacy system infrastructure and norms (e.g., the UK, likely to be more widespread due to the public nature of data rather than private and siloed in the US). It will be prevalent in many aspects of the metaverse.

Again, it's neither rigid determinism nor infallible; it uses just maths and science to give you a probability. It also does not have to be perfect to gain popularity, just better than the average human. Finally, its use will not be because of the deep state or Zuck made us; it will be a (relatively) conscious decision.
The transition in practice: Ask the priest → ask yourself → ask Jeeves → Jeeves will predict the answer you may desire amongst others and tell you.Many suggest that to be a severe threat AI must first develop sentience and meatspace integrations but what if it might get there in other more subversive ways?
Once AI masters language (dubbed the ‘human OS’ by Senor Yuval), which we use to translate imagination into aspects outside our DNA, such as human rights, laws, culture, money, and nations, it can begin to mess around with some of those constructs on its own as for the first time, we won’t be the most intelligent beings in our human existence (but a distinction between egoism and humanism must be made).
AI evolution is already surpassing the average human mastery of language, and autonomous agent evolution is moving steadily. As such, the ability to develop deep relationships with humans (mass intimacy) is improving and compounding; the longer we engage and the more data used, the more intimate the systems become (see general ML).
TLDR: you dont need chips to control people; storytelling is probably enough. If the previous usage of AI in virtual environments were already enough to cause significant problems, the new guard would likely be far more disconcerting.
The Realignment:
Is the age of men over? 
Much has been written about the broader intersection of humanity and AI.
In terms of general crypto<>AI, they are uniquely synergistic; crypto will benefit from the explosion of AI proliferation and activity, and AI will rely on crypto as an enabler (access to permissionless rails and services) and a counterbalance (verification, governance, and realignment).
Regarding the subject at hand, the recent exponential increase in AI processing power has dramatically altered the surveillance and control landscape. If much of the current surveillance data has been underutilised due to a lack of a scalable workforce, AI bridges the gap between all the databases left unqueried, meaning the implications on autonomy need some future-proofing.
Browsing the internet through an externally owned web server is like playing autonomy chess (below) against La Place’s demon (total atomic and temporal knowledge). Even though there is still a certain sense of autonomy and the tech is still in its relative infancy, the future odds in the metaverse are stacked without sufficient privacy as the one-sided demon gets even more leverage.
Thus far, the centralisation of AI processing power and dataset aggregation has meant that those leveraging those tools have the upper hand regarding social control and subjugation; these systems will only become more powerful as time goes on, absorbing more knowledge into an exponentially snowballing behemoth.

Whilst we tread the precipice of “Thou shalt not make a machine in the likeness of a human mind [...]”, these systems are very useful in organising the chaos of the Internet and will be even more so with the proliferation of content and experiences in the metaverse.
But what do people actually want?A recent study suggests general objections to the opaque collection and use of personal data for algorithmic personalisation to curate news signalling and even more so for those with political connotations. However, the same study found an acceptability gap for algorithmic personalisation in general in favour of collecting personal data. Suggesting a need for transparent algorithmic personalisation based on consensual and modifiable interactions with the user.
As such, the case in which the AI is eradicated is unlikely and unfavourable, and the one where total privacy is enforced is one where the metaverse becomes either more unorderly or quiet. As neither seems likely nor wanted, it becomes a case of realigning access and the intentions of the tool to achieve the transformation from subjugation to empowerment.

In terms of changing access, this would mean embracing decentralised and open-source AI, transitioning from a server-side relationship to a more client-facing one. Regarding intentions, personalised and ‘trusted’ AIs may develop a type of attorney-client relationship with the user (loyal, discreet, and without conflicts of interest). To take the analogy further, personalised AIs would act as a go-between (similar to how lawyers represent in courts) with every data interaction, negotiating a fair trade between access to services and disclosure of data. Upholding rights and efficiently reading and understanding terms of service, only accepting those that fit personalised preferences or (potentially) for payment of data; where manipulation can be mitigated by compensation (plz someone build this). Moreover, personal data can be encrypted, stored locally or in encrypted personal servers, in decentralised systems, or for those in the middle ground through trusted custodians such as bottom-up data-trusts, increasing both consent and privacy.
Furthermore, these personal AIs could assist in several insurgent ways. Suspicion in programmatic advertising could be helped by increasing transparency regarding the origin, arrival, and intentions of content through sourcing disclosures.

Disclaimer Example: paid for by The IRA - AKA Kremlin Troll Farm, CPM: $23 (incl. 33% premium for political and 37% for foreign content). Alternatively, embracing intellectual humility to combat the polarisation of views. Personalised AI could serve as anti-rabbit holes that occasionally offer optional contradictory articles or prompts based on changeable preferences and users' content consumption (devil’s advocate protocol).
These use cases are exploratory, but the proliferation of client-side/personalised AI combined with siloed personal databanks would certainly combat eroding objectivity and polarisation, or at least make it optional or compensated. Centralised AIs would still exist on the server side of the relationship, but decentralised AIs would level the playing field (below). In this scenario, autonomy becomes more of a battle of compute.

Phygital Algorithmic Governance:
Is the meatspace age of men over? The metaverse will also frequently cross over into the physical.
AI in data tracking and subsequent content organisation is only one-use case; society is also trending towards algorithmic governance in other areas, and can be seen through the gradual emergence of smart cities and the assistance of AI (and IoT) to control such spaces.
Algorithmic governance can be broadly understood as implementing automation to regulate aspects of a given system. In the same way that the metaverse has been discussed as a limited environment for ultimate control, smart cities can be seen as “[...] bounded, knowable, and manageable…that can be steered and controlled in mechanical, linear ways''.
Again, it is important to ensure that systems are created with the right intentions to avoid negative outcomes such as the erosion of autonomy, in this instance both internal and external, the maintenance of relatively uninhibited reason and subsequent decision-making.
Many shorter-term risks to autonomy have been identified in the algorithmic governance of smart cities that can be applied to the more physical integrations of the metaverse, including technocratic reductionism, governance corporatisation and platformisation, excessive surveillance, and democratic backsliding.
Within these confines, there may also be the potential for algorithms to enhance existing social biases and make inevitable and potentially irrevocable mistakes without sufficient privacy or the ability to opt-out.
Thus far, many of these systems have sought to automate more mundane aspects such as traffic, public transport and energy efficiency; in terms of futureproofing in the shorter term, other areas, including workplace efficiency, location tracking, robocops, and convincing undercover agents (M-AI-6, C-AI-A et al.), are comparatively concerning as are general threats i.e., reduced barriers to entry for bioweapon design. However, these concerns are more relevant to reducing autonomy from human to human using AI.
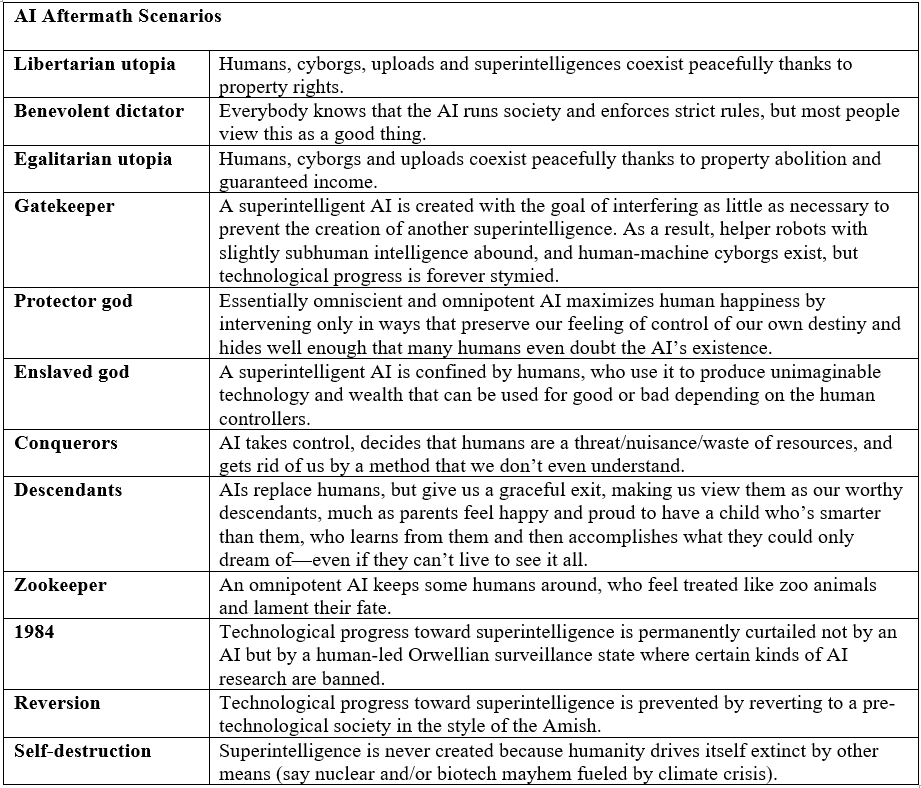
The full spectrum of autonomous reduction can be shown by Max Tegmark’s next 10,000 years tables (more to indicate the extent of futureproofing required rather than for extensive discussion).

But how to improve the chances of resisting either AI<>human or human<(using AI)>human hegemony? Like the self-driving car notion, these systems operate optimally with increased transparency and decreased privacy (from the subjects) alongside total participation. But optimal is subjective in this case, as it exacerbates biases considered harmful and defines one-sided control rather than overall improvements. As such, the closest to optimal system will likely never be all-encompassing and should not be mandatory. There needs to be some grey areas for compromise, as perfect systems are impossible in this case. Some things can and likely should be automated, and others should rely on traditional jurisprudence (greyer). AI, again, is not deterministic; it can be used to reduce hobgoblinery and increase scientific research but at what cost and to further who’s aims?
Privacy can again be a shield from overly encroaching systems and a way to opt out of such control and preserve some form of autonomy. Perhaps ending up in states of Gatekeeper (finite but sufficient innovation), Protector god (at least perceptions of autonomy), or Enslaved God (need better distribution of AI to avoid one-sided control or 1984).
Of course, this may all never happen; we are still far away from 1) comprehension of the brain and further from the mind for hacking, 2) AI sentience for rogue intentions, and 3) mass AI <> physical integrations (robocops). Also, as science often adds to what we do know, it often reveals as much about what we don’t.
"Science progresses one funeral at a time". - Planck.
Just in case, healthy relationships and a well-rounded and equitable distribution of AI (as described above) throughout society would help level the playing field. Furthermore, a decentralised (defended by ‘trusted AIs’) and modular approach to algorithmic governance in the metaverse and smart cities will limit the errors and one-sidedness and provide zones for experimentation.
Whilst alarming, a distinction should be made between egoism and humanism. Although it will be hard to relinquish some of the autonomy mentioned above, wrested over centuries from the clouds, various decisions will likely be better made with assistance from our new algorithmic deities. How much (or little) should be surrendered will inevitably be contextual, so the solution (discussed later) should match.
Additionally, combining neutral infrastructure, cryptographically ensured rights to exit, opt-in or mandatory disclosure of AI, and privacy-preserving optionality will all be necessary to help avoid scary outcomes.
Censorship and Control:
Is the exessive usurpation of internal moral autonomy sensible? 
Surveillance and censorship go hand in hand.
When barriers to entry for publication and speech are lowered, content may be unsavoury or, in some cases, illegal - leading to potential requirements for censorship. But if the metaverse is going to be an oasis for self-expression that doesn't inhibit the autonomous agent, it requires verifiable freedom of expression and credible neutrality at the base layer. For brevity, free speech and the freedom to express (content creation), access (geofencing), and transact (value transfer) will be considered the same.
Censorship is problematic for a variety of reasons:
Norms of acceptability are contextual and subjective. Inevitably, those in powerful positions become censors, liable to censor anything that undermines that power.
It is the subtle erosion of the ambiguity, the scary relegation of humility, the mayhaps, perhaps or who knows. It is ossifying through its lack of humility and confidence in a static 'truth', constantly trying to be right rather than less wrong. This can lead to the premature gating of progressive (and sometimes beneficial) notions (see Galileo or Alan Turing) as the controllers of the time (influenced by mob and state) oscillate between short-term trends in bowdlerism to optimise chances of (re)election, long-lasting recognition, and more recently, avoidance of cancellation.
In the face of many uncertainties and constant upgrades, it's scary to think that people can be so confident of many static truths, especially when you look back at all the people who undoubtedly had confidence in theirs.
But they can lead to erosions of trust (subversive bans), usurpation of internal moral autonomy (decisions on virtue made by external parties) and homogenisation of virtue (diversity of opinion and self-expression limited).
In terms of nation-states, censorship is drastically varied. Whilst comparatively permissive, Western society has frequent run-ins with overt censorship, and more subversive, shadow censorship by proxy, deceit or jawboning continues to rise, and the dream of 'net neutrality' is a retreating fad. Although overt censorship occurs, state censorship is often behind the scenes and implemented through corporations (jawboning). This is problematic because if the extent to which censorship is employed is not overtly clear, the potential for outrage to leverage radical social enforcement is significantly diminished, letting the problem continue. Censorship should be overtly justified if preferred at a state level.
Corporate censorship, implemented by unelected officials, is impractical (constant and global) and subjective (open to regime/ideological capture). Whilst hard to discern the line, monopolies on content have increasing sway to censor, implement morality clauses or, in extreme cases, organise synchronised embargoes of free speech from supposedly independent organisations. Although censorship within walled gardens is a relative prerogative as long as it is in good faith. But these gardens now command such monopolies that they have transitioned into a quasi-base layer, and censorship restrictions that apply to the state do not extend to the private sector. Realistically, corporations may instead be rid of this responsibility, as a choice between action (manipulation) and inaction (carelessness) results in a Catch-22 for optics and profit margins; it is unlikely many will oppose being lifted of the responsibility (or encouragement) to censor.
Privacy is essential to circumvent censorship and create a space for free expression and autonomy; however, in this instance, it is only one part of the solution. The base layer (rather than the applications) should likely remain open, uniform and non-politically motivated, without space for swift and easy change. Not only should the baselayer be designed to be neutral, where it cannot discriminate or adjudicate, but it should also be credibly neutral - verifiable to anyone who wants to check.
The transition: having to saying go fuck yourself —> you cannot get fucked.Not to say you can't make decisions, but their outcomes should likely remain relatively transient.
In the metaverse, there will be separate realms in which censorship will undoubtedly be employed, again the prerogative of the controllers of the space and the inhabitants’ choice to enter a filtered space. In more decentralised (open) instances, most of the meaningful activity will occur at the base layer (ideally censorship-resistant) to limit its impact, and there is no right to algorithmic popularity (freedom of speech does not equal freedom of reach).
For the remainder, censorship parameters and governance will likely be decided modularly by their community members and may rely on several optional reputation systems (discussed later) to determine access to edit, publish, or even enter. However, accountability may sometimes prove difficult due to the lack of identifiability of the creator(s).
Censorship will likely be implemented hierarchically in more centralised spaces that operate partially using a decentralised base layer. However, consequences will be reduced with increased alternatives and a neutral base layer. In more closed worlds that mirror current centralised platforms, censorship of both financial and social activity will be more critical and de-platforming more devastating but useful for those who prefer heavily censored environments.
Money & Censorship:
Can money be used to undermine autonomy?
Money is a significant avenue for self-expression and communication, indicating preferences on various avenues such as sex, politics, religion, and different psychological traits. Financial surveillance (overview), a precursor to censorship, is an impactful and equally modern phenomenon that deserves comment regarding privacy and freedom.

Financial privacy has been eroding alongside physical cash (peer-to-peer and more private), replaced by state-accessible banks and credit systems. Whilst financial privacy laws have hardly changed since various landmark cases corroded opacity: Banking Secrecy Act (increased recording), US vs Miller (third-party doctrine), the Patriot Act (increased reporting) and global adoption of norms such as the Common Reporting Standard and the facilitation of global financial data sharing.

As per the constant theme, since exchange became primarily through digital means, the detail and granularity of transactions became increasingly vibrant, facilitating more widespread and colourful surveillance. Alongside the practical decline of privacy is the general acceptance of this default lack of privacy concerning financial data. As financial interactions map and facilitate expression - forms of dissent (protests) are stifled with excess surveillance.

Financial surveillance is also a precursor to censorship. Although usually associated with some faraway regimes, outright state financial censorship in the US is done both domestically and internationally in the form of sanctions, asset seizures (a tidy $68.8bn from 2000-2020), freezes and capital controls, maybe good, maybe not so good. Whereas state-outsourced and more subversive corporate censorship, outsourced through corporations such as Visa and MasterCard, can and have removed access based on moralistic decisions over what users can read, say, and enjoy (decisions on virtue made elsewhere).
An area of surveillance that will become increasingly important (especially in light of recent economic events, the lack of new FDIC charters aggregating banking control, and general borrowing from the past to pay for the future) is the implementation of central bank digital currencies (CBDCs). Whilst leveraging slightly similar technologies, they are the antithesis of decentralised money. A national central bank would facilitate issuance, backing and control whilst coordinating with the treasury, Congress, and international banking consensus.

Aside from the economic consequences, CBDCs remove the already limited financial privacy currently existing, increasing surveillance by total control. This Faustian bargain, if designs pursue the consolidation of power, would likely a) remove the intermediaries (commercial banks) providing the last shred of privacy barrier, replacing it with an open backdoor for extensive and unchecked central bank and state surveillance coordination b) at best and unlikely, channelled through private banks that entertain the same minimal privacies that exist today, but with a backdoor.

CBDCs can exacerbate unilateral control and the consolidation of an already politicised banking system. The freezing and seizure of assets can become more surgically accurate (at a clustered or individual level) and efficient by establishing a direct line between the state and citizens. Programmability enables the ease of tracking, reversal of transactions or introducing arbitrary rules and/or spending limits and controls on, for example, demerit goods alongside undermining the current financial markets by reducing credit availability and the private supply of loans and general centralised cybersecurity risks. Whilst these currencies would exist on a spectrum of anticipated coercion (minimalist to maximalist), a usual defence of CBDCs is as follows: money is already digital, a lack of privacy is already built into the system, and the more sinister aspects would only be used in totalitarian regimes due to sufficient barriers in Western societies. Set against the ol’ Kymer Rouge adage - “it is always better to go too far than not far enough.”… sounds kinda like a bad idea.
Alternatives? Decentralised money converts some of the civil liberty-enhancing benefits of cash into the digital realm. Some advocate for a cash-like (with traditional liability insurance) continuance of digital money, utilising centralised issuance but decentralised circulation and payment processing through open-source hardware solutions such as ECASH.
Further along the state nihilist spectrum are currencies that decentralise issuance, circulation, and settlement. However, these are imperfect conduits for private transactions due to currently inherent conflicts between ledger-based systems (solving double spend) and privacy (touched on later). If solved, these optionally compliant versions of decentralised money are, in theory, censorship-resistant, self-sovereign and thus conducive to autonomy. However, this is unlikely to be a winner-takes-all market, as enlightened middlemen may adopt various cryptographic primitives for self-preservation.

Reputation Systems & Privacy:
Another way to combat hobgoblins? “A good reputation is more valuable than money.” - Publilius Syrus

This section will evolve from solely discussing various externalities to reputation systems. They can serve as part of the problem or the solution. Cautious reputation systems may incentivise behaviour in the metaverse to combat a potential increase in hobgoblinery enabled by increased privacy.
Identity and reputation are interlinked, although public identity (the atomic actor) defines the intrinsic characteristics of an entity (PII), whereas reputation is concerned with its outward-facing characteristics.
Reputations are reflections of trust that hold people accountable for their behaviour. When people interact with one another or other entities, past interactions inform them about their abilities and dispositions. Furthermore, the expectation of effect on current behaviour on future exchanges creates incentives for acceptable actions, known as shadows of the future or indirect reciprocity.
Historically, reputation was primarily facilitated through gossip, primitive cultural instruments and old-school social networks. As technology developed, reputation was enhanced by instruments such as letters of recommendation from trusted emissaries, and identity moved from word of mouth to various ledgers.
But trust between strangers is harder to build. As networks grew, modular and local reputation and identity became difficult to maintain as trust was hard to scale. In modern Western society, the role of trust in reputation systems has been primarily replaced by corporations (for an overview). Although improving trust, these systems are economically siloed and liable to manipulation and attack. Whereas states replaced trust for verifying the more fundamental aspects of identity, the physical implementations are slowly being replaced by trackable digital counterparts.
Decentralised or self-sovereign identities (SSIs), part of the open metaverse web stack, allow users to control their digital identities without centralised intermediaries. Instead, distributing the responsibility of maintaining and validating reputations across a network of participants. Theoretically allowing users to create, store and share personal identifiers with customisable levels of privacy.

Despite a few quasi-experiments with centralised partners, their integration with or separation from legacy systems is undecided.
Excessive Social Scoring:
When is it too much?It is important to evaluate intentions and consequences to avoid a system that facilitates more harm than protection. Scoring human behaviour can be problematic for several reasons that undermine autonomy (both internal and external). Despite incentivising behaviour, excessive reputation systems have the potential to become overly encroaching and conversely limiting based on the balance of autonomy, paternalism and consent involved. Overly monolithic and mandatory reputation scores may decrease mobility and increase social stratification.
There are various reputation systems already in effect across various levels of centralisation. China’s well-hobgoblinised social credit system. Similarly, despite China’s stigmatisation, various systems are already in place in the Western world, some widely accepted and others critiqued. So far, the consequences and scope of the categorisation of social standing have remained mostly financial and largely siloed. However, the net is widening into what can and cannot be included in indexes for control.
What to prioritise?The core considerations with any reputation system should likely remain consent and visibility, context, and privacy to tread the fine line of something being done to (arbitrarily given) or for (voluntarily earned) one’s detriment or benefit.
Consent and Visibility:
Currently, corporate-controlled reputation systems exist in an alegal grey area with often no means for appeal when incorrect assertions or attributions result in externalities such as false positives. Decentralised reputation systems, even more alegal, require consideration to combat false attestations and immutability (especially in instances such as soulbound reputation primitives).
In more closed metaverses, reputation systems will likely be designed based on current legal considerations such as purpose limitation, data minimisation, and consent and access will depend on permissible purpose. This results in the user agreeing to be rated despite that agreement having been subversively obtained in many circumstances.
On open metaverse rails, transparency is a relatively Hobson’s choice (as expanded on later); activity can be used in ratings by default, leading to permissionless reputation metrics with little consent.
Given that a user consents to be a part of the reputation system, careful considerations need to be made, including key and aggregation binding and anonymity/unlinkability.
Context:
As the scope for metaverse activity widens beyond financial applications, so does the scope for including alternative metrics for reputation scoring. Based on both ludic and non-ludic activities and anything in between.
For example, using Red Dead Honour scores to secure a loan may seem far-fetched, but these systems will become increasingly integrated with the convergence of gaming, finance, and digital assets. However, disclosure of such scores should remain consensual rather than transparent by default.

Optionality:
Implementing optional and selective privacy in reputation systems is necessary to avoid excessive and unconsenting social scoring. There is a general notion that information systems without full information fail to evolve and function effectively. Specifically, in reputation systems, indirect reciprocity can be hampered when systems have less data.
Whilst true, in this circumstance, that is acceptable, as ‘perfection’ would lead to undue limitations, primarily when systems utilise automated algorithms. Gaps in the systems facilitated by privacy may ensure sufficient movement for expression while maintaining behavioural incentives. Furthermore, when making reputational systems optional. Those who use the system can achieve seniority through opt-in-trustworthiness. Privacy is not only essential to combat the over-encroachment of these systems but also to facilitate helpful feedback and rating without fear of recourse.
Cautious and Contextual Reputation:
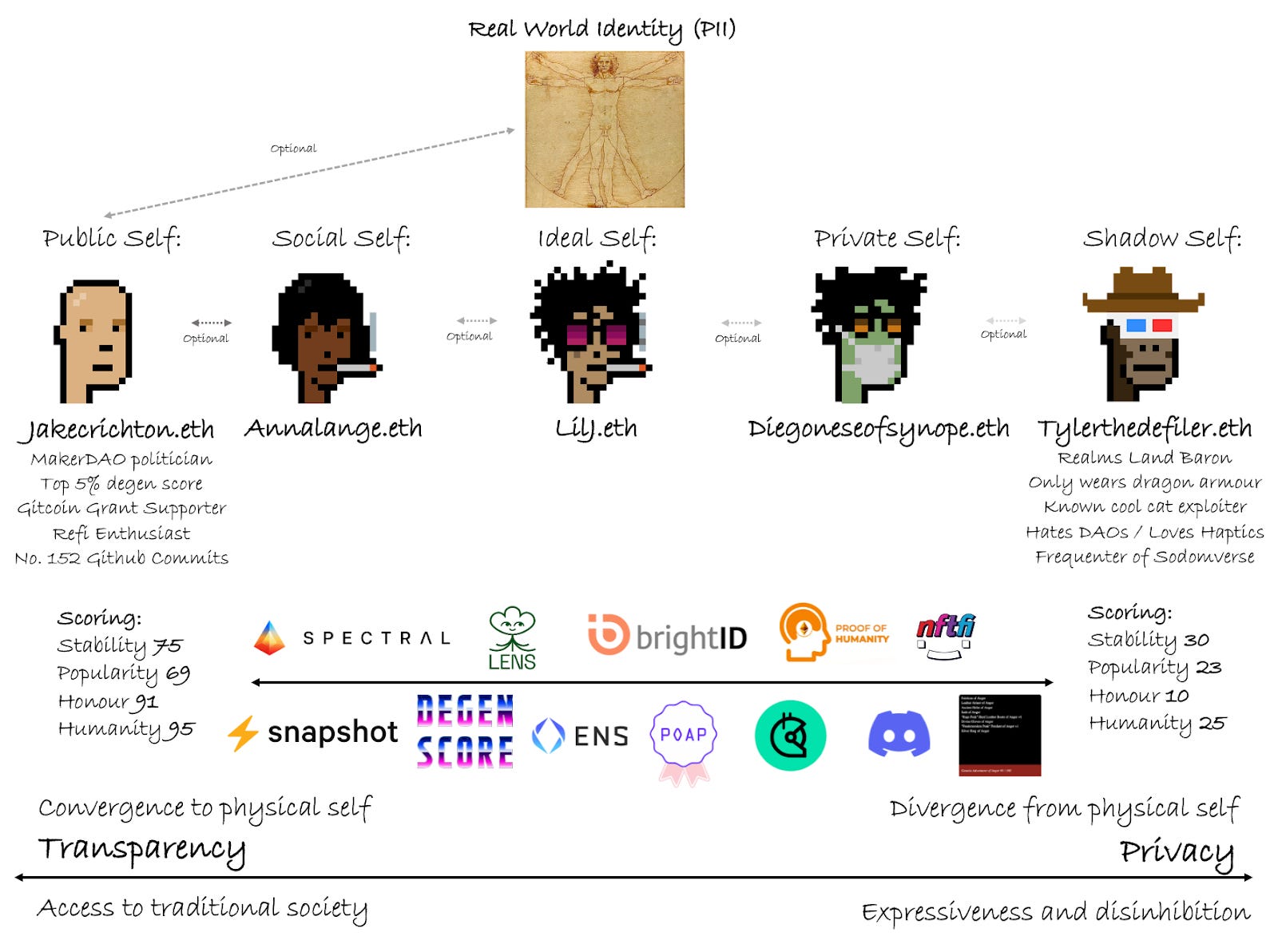
Users will have the ability to create several pseudonymous reputations to choose from. The amount of association with reputation scoring will likely be contextual and with consent from the user, the same as disclosure of data and/or linkage with PII.
From their chosen public-facing criterion, others will be able to ascertain behavioural and characteristic identifiers of other users based on fantastical and ordinary metrics. For example, identity and reputation will likely rely on time spent as proof of work and those that are ‘lived’ more frequently, combined with potential PII, will likely dictate a humanity score to identify non-humans.
But living in the shade isn't possible if you want to do things in spaces that affect others. These criteria may divulge increasingly important information based on more convergence to their real-world identity; as such, those identities will enjoy more access to goods, services and experiences, whereas those that remain more private may serve as the metaverse version of 'incognito mode' to facilitate excess expressiveness but inevitably curb access to more public areas if the associated expression is not widely accepted.
Onchain Transparency and Pseudonymity:
Surveillance conducive?We cannot expect governments, corporations, or other large, faceless organizations to grant us privacy out of their beneficence. It is to their advantage to speak of us, and we should expect that they will speak.” - Hughes.
Privacy remains highly politicised and nuanced regarding its intersection with decentralised networks. Much like the initial omission of payment rails from the original internet, the initial omission of privacy from the open metaverse stack may prove costly; this is not only relevant to financial information but also to all metaverse-related behavioural activities. As per, less privacy = less autonomy.
A simplified blockchain-plumbed solution to combat excess control in the digital realm would embrace encryption to design a new layer of trust to facilitate coordination, replacing centralised intermediaries with decentralised, permissionless and transparent public ledgers. However, with this transparency comes an obvious problem for privacy; most networks were not created to ensure anonymity - if they had, they may have faced severe headwinds with scaling. Instead, they focused on efficiency and other security in the short term. Many protocols have subsequently been shut down or closed for positioning privacy as their raison d’etre.
NB: A lack of built-in privacy functionality at the time of inception was likely due to technical limitations rather than a tactical choice for preservation or ideological ambition.
Regulators often stigmatise blockchains for their ability to hide, primarily financial, hobgoblin activity. While this is possible, as it is on most payment rails, activity predominantly occurs on pseudonymous public blockchains, where the public key renders various information transparent by default - a very useful policing aid if unlinkability can be broken. As such, a more privacy-focused middle ground must be found to preserve autonomy.
Now, utilising increasingly effective techniques, such as clustering, taint analysis, tracking chain hopping, temporal dissection, various OSINT strategies, and surveillance vectors from popular on-ramps render privacy and, as a byproduct, on-chain pseudonymity relatively obsolete. Once a wallet address is attached to an entity (which is relatively trivial if they are active or ‘valuable’ enough), surveillance is simple - facilitating a comparatively faster and even less consensual version than exists in legacy systems. Fortunately, this is less impactful, as entities and individuals are mindful of privacy when storing more sensitive data on-chain. However, this will not always be the case for the open metaverse when coordination will rely significantly on blockchains.

Whilst the more cypherpunk aspects are being eroded through forced surrenders such as AML/KYC integration and instances such as OFAC-sanctioned code, compelling compliance through fear of hobgoblins. As the legal battle continues, US citizens require permission to remove assets - not ideal for global permissionless networks (kruptós < compliant).
To maintain a semblance of effective pseudonymity (given the lack of available tools), one must be either incredibly paranoid, technically gifted or have on-ramped before KYC came into play and remain isolated from those venues since - those wishing to off-ramp (reverse exit) pseudonymously face various issues. However, at the bare minimum, pseudonymous encryption at least increases the cost of state coercion to make it unsustainable.
But the question remains: is building a transparent opt-in system where pseudonymity is practically redundant a good idea for those who opt in? We’ll see later.
Free-Market Autonomy:
How much does autonomy cost?
In the current prosumer paradigm, privacy has a price, and the adtech facilitated more recently by a lack thereof paid for the internet as we know it.
Coase's Theorem states that in competitive markets, with no transaction costs and clear property rights, parties will negotiate an efficient outcome. Through this price discovery, control over data will go to the party who values it most, regardless of the right to ownership.
But these aren't efficient markets, and various factors affect the free market rate. Information, asymmetry (dark patterns, bundled consent, etc.), blurry property rights, legal interventions (public task, legitimate and vital interest) and expensive transaction costs.
Various surveys assert that many claim to value privacy, but few tend to act on it; the aggregate privacy calculus tends to value free services over privacy thus far. Despite concerns, users cannot eat the free cake and remain private.

There are partial opt-outs from the economy of influence. Premium services offer the exodus from ads, but derivative data remains tracked, and users remain influenceable onsite and to 3rd parties.

{kind=link}
{kind=link}
But ads are not inherently evil; they pay for things that otherwise wouldn't exist - like the scale of today's internet, and once you offer free services, it’s hard to transition to a paid model. But we must separate the old externalities from the more impactful ones that could exist. Extrapolating into the metaverse, there will be closed virtual worlds that are free to use but paid for by data → manipulation, and as mentioned above, these will likely trend towards hypermanipulation. There will presumably be paid-for tiers where users can opt-out, autonomy becomes a luxury, and the remaining will be monetised.
It's uncontroversial to suggest that many users, through significant time, space and unknowns, are ill-equipped to price the long-term consequences against the present-day benefits of free services. People tend to undervalue a commodity they think they have already lost, and realistically, citizens have had so far limited options for data privacy.
This can change with the potential lowering of transaction costs and increasing property rights over data. Individual users can negotiate an efficient trade for their autonomy in centralised platforms. In more decentralised ones, the free-to-use/manipulation dilemma becomes removed with other incentive mechanisms.
However, it's a trade unlikely to make many rich anytime soon. While older stats, attempting to ground the narcissism of privacy, put the minimal per-user cost of influence at $0.005 (for basic info), the increasing scope of information available in the metaverse may fetch a higher price.
Threading the Needle:
Where forth art though pragmatic solution?There is no solution to privacy in the metaverse that doesn't require concessions, but the option for more than in Web2, and more than currently exists in Web3, seems a reasonable starting point.

What’s wrong with total transparency? Conversely, an alternative to more private systems would be to make everything more transparent. Transparent systems are rightly lauded for their ability to achieve accountability, increase trust, and prevent abuses of power through monitoring. However, an open metaverse built entirely on transparent rails would likely have several scalable externalities on autonomy that are more concerning than the existing setup:
Decentralised self-censorship: inhibitions from existing ‘naked’ in a surveyable landscape capable of massive sousveillance, not just from the mistrusted institutions → audience effect against mass creativity and expression (a population of hyper scalable and vigilant hedge-watchers).
Existential chilling effects: critics suggest that transparency ironically amplifies chilling effects as subjects of surveillance are acutely aware of the extent to which they are monitored.
Fragility: due to information asymmetries from those outside the system (below).

Total transparency is unrealistic due to the aforementioned underlying power asymmetries, legacy patterns, institutional constraints and broader security concerns. Entities will always seek to conceal personal, corporate and national secrets.
Information asymmetry can lead to various imbalances and subsequent arbitrage vectors across several constructs:
Person-to-person: cybercrime.
Markets: adverse selection.
Corporate-to-person: surveillance capitalism.
Corporate-to-corporate: espionage.
State-to-person: surveillance state.
State-to-state: global cyberwarfare.
The current asymmetry causing the above-mentioned issues is a product of decreased privacy on the user level and decreased transparency at a state and corporate level - increasing transparency intra-system is unlikely to flip this dynamic. With all these (and more) vectors for attack, misplaced transparency can seem like a mandate filled with hope but lacking practicality or robustness.
Conversely, transparency can become a tool for eroding trust as people become complacent in their false sense of security, whilst those outside the system are free to leverage their advantage. Designing systems based on mistrust rather than trust provides the answer to safeguarding privacy rights in the surveillance age.
What about those hobgoblins and beneficial data-sharing? Whilst reducing the externalities of state and corporate surveillance, extremely private or excessively siloed systems would have several issues, such as:
Increase the possibility for abuse and general hobgoblinery with minimal accountability.
Significantly inhibit usability and functionality in the metaverse, especially given the need for interoperability, synchronicity, and composability (although privacy may increase competitive compatibility or portability).
Hamper data collection in beneficial instances, such as healthcare.
Given all this, there is a need for a system that enhances privacy as a default, requires comprehensive consent when it is lifted, potential remuneration and granular selectivity in instances of necessary disclosure to avoid by-catch whilst maintaining the functionality of systems and the sharing of data for beneficial purposes. Furthermore, there is a need for this system to be flexible to the needs of the individual and the situation.
Reviewing Nissenbaum’s contextual integrity (2009) and its four major claims:
That privacy is ensured by ‘appropriate’ flows of information.
Appropriate flows conform to contextual norms.
These norms refer to five independent categories: data subject, sender, recipient, type and transmission.
Privacy is based on ethical concerns that evolve over time.
Maintaining a semblance of contextual integrity in the digital realm will vary over a range of instances, such as:
The type of information being shared, for example, financial data, retinal movement, or game state log. Some will require more privacy than others, depending on the sensitivity or the impact of leverage of the data.
The roles of the sender and recipient, e.g., interpersonal (private), interpersonal (business), B2B, etc. Privacy requirements may also change depending on the number of interactions (vectors to infringe on others) in the space in question.
The purpose for information sharing, e.g., access to an area, proving the integrity of ownership or purpose of a transaction. Some disclosure of data will be required for compliance or access.
The constraints under which the information is shared - full disclosure or mitigation strategies as to the extent of data usage.
Despite being a helpful framework for emphasising how privacy solutions are not as clear-cut as a holistic reduction in the data flow, Nissenbaum's claim may require refinement to apply to the metaverse, given its complexity, evolution, and fluidity of contexts. With close examination, many specific instances are open to interpretation, and subsequent political and corporate influence in flimsy laws make them exploitable enough to erode to the point of redundancy.
Can states solve this? Reliance on state regulation (the most well-cited solution) may be problematic for several reasons:
The constantly moving target of contextual data privacy alongside a constant desire to implement backdoors (state and corporate assimilation) makes it hard for legislators to a) keep up, b) agree with one another c) keep up because they can't agree with one another.
Top-down imposed regulation of data privacy may only eventually favour the large corporations with legal budgets to address and subvert new rules, leaving smaller (and perhaps more privacy-focused) challengers to become boxed out.
There is a lack of requirement to adopt a one-size-fits-all approach due to the meta-verse-utopia characteristics.
Due to its global nature, it is unlikely that independent jurisdictional legislation will cooperate sufficiently, without arbitrage from dissenting or opportunistic nations, to be successful.
Regarding the alternative, Lex Cryptographia, a technologically sponsored solution, could be found through bottom-up adjudication, allowing the user to decide contextual integrity using hard-coded laws, which are significantly more challenging to erode and subvert. There are many reasons why this solution is more elegant, discussed and outlined below as the autonomy-focused solution.
An Autonomy Focused Solution:
This is the way? “The technologies of the past did not allow for strong privacy, but electronic technologies do.” - Hughes.
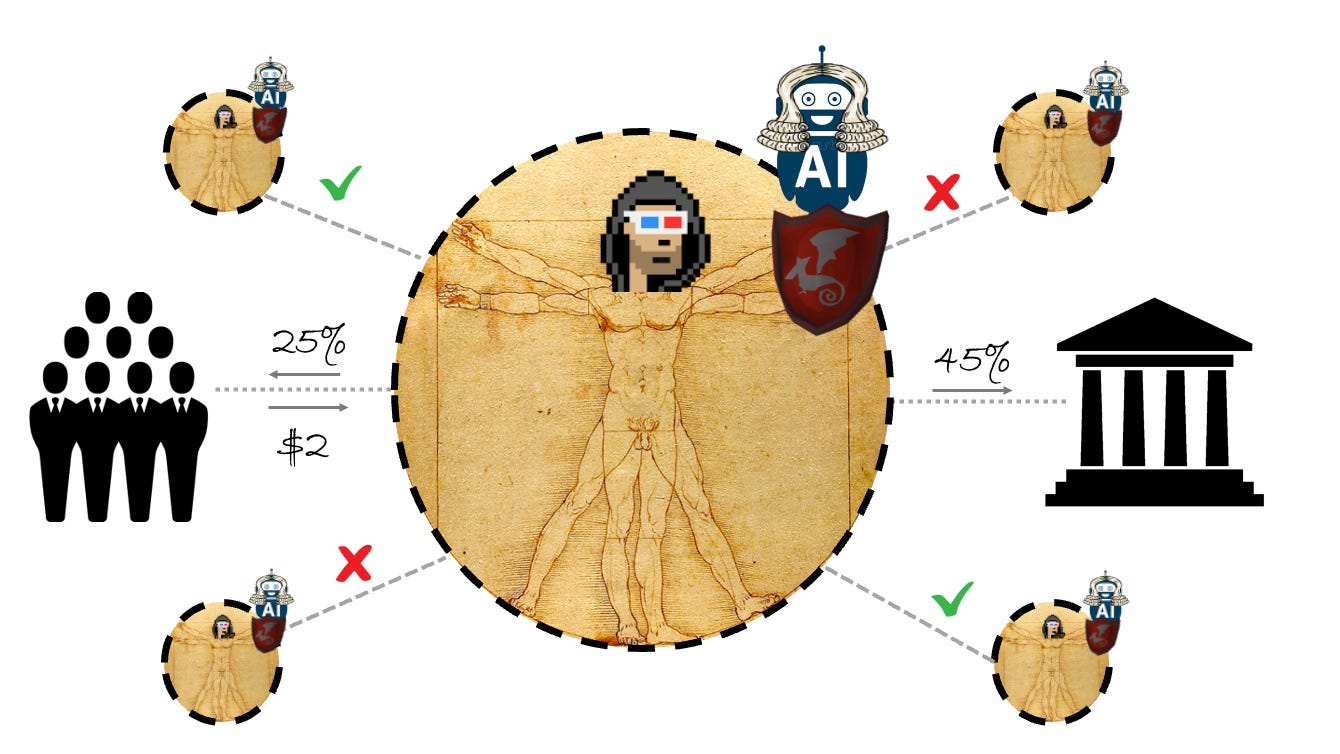
The most flexible, and thus widely contextually applicable, solution to achieving the metaverse utopia gives users unprecedented agency in data management and privacy solutions across different layers, norms, jurisdictions, relationships, and ethical and economic preferences. Users will thus be granted the external autonomy (choice to act) to design a solution beneficial for internal autonomy (self-governance), creating a positive feedback loop that enables a holistic increase in autonomy.
Regarding the pragmatic technological solutions mentioned throughout, they are broadly focused on reducing the amount of unprecedented data flow towards those looking to leverage control and influence through various means of encryption whilst ensuring voluntary compliance in situations where privacy is not preferable.
Whilst these solutions end with consent on a more granular individual level, they can also be programmatically applied (and opted in by users) on a ‘world’ level; in more decentralised spaces, rules will be voted on by owners or delegated to more trusted and transparent protocol politicians or delegates focused specifically on privacy, allowing for a multi-layered contextual approach based on several complementary and integrated factors discussed throughout:
Positioning decentralised identity as the agency hub with reputation systems.
Emphasising user control, data ownership, selective disclosure, authentication techniques, isolated data sets and security, and proof of personhood.
Multiple identities for multiple purposes; ‘incognito’ mode for more expressiveness. Fused with optional reputational systems to enforce accountability and reconcile anonymity and access.
These ‘control rooms’ allow users to manage and own aspects of their digital interactions and identity, giving optional privacy and controlling the outflows of data.
Combined with decentralised storage and edge computing. At an individual, community or private level, such as bottom-up data trusts. Rebalancing transparency and trust from those who lost it to those who can provably earn it.
Fusing public blockchains with end-to-end encryption using zero-knowledge proofs (zethereum), zk-EVMs, homomorphic encryption, account abstraction, AI agent canaries, privacy pools, or more privacy-focused L1s/Rollups.
Facilitating compliant privacy in necessary instances but not by default - requires more action from legacy law enforcement than in recent years but not historically unusual; legal requests can be met sufficiently with selective disclosure to avoid bycatch. The transition from ‘nothing to hide’ to ‘selectively hiding in plain sight’.
Requires significant innovation for scaling, privacy and robustness - optimised smart contract integration to follow (programmable privacy).
Needs to square fragmentation across asset, application and network levels.
Preserving credibly neutral access at the base layer.
Commitment to impartial sovereign protocols that cannot discern between the usage or transmission of said things or value.
Censorship is to be implemented in specific virtual worlds depending on community wishes, and levels of privacy are to be afforded depending on levels of infringement on others and/or debauchery.
Using insurgent and decentralised AIs with attorney-client privilege for consent, negotiation, management, understanding and practicality.
Navigating parameters on disclosures and use of data. Leading to more manageable and informed consent and personalisation of preferences across multiple identities.
Mitigating the extent of influence, data collection, and potentially negotiating compensation (however small) for sharing certain instances.
Closed virtual worlds may operate with different data collection policies; full disclosure is required to determine the access preference.
Ideally, with scalable 3rd party oversight to prevent AI collusion, harnessing federated learning, SMPC & negotiation training.
Innovation in re-architecting network design, move towards peer-to-peer, DSNA and more intimate systems.
Reducing externalities from influence optimisation in centralised system architecture.
Self-hosting of servers/clients.
There are, as yet, no polished answers. However, a privacy solution that caters to most people's needs whilst decreasing unnecessary hobgoblinery and allowing a reasonable area for expression is worth aiming for. Additionally, there are other factors to consider: extensive technological improvements required, GDPR concerns, and the intersection of hardware providers.
In the metaverse, due to the divergence between traditional law and order and those in modern systems, innovation will invariably outpace the law unless there is total restructuring or additional purpose-built legislation. So a fusion of specific corporate committees (in closed spaces), decentralised law and order (in more open ones) and code as law (at the baselayer) will likely fill the void.
In the interim, there will be significant pushback from legacy regulators across different contexts of privacy applications, especially in financial anonymity (the biggest home advantage of all time). The more significant the pushback, the more justification for the solution. However, only when provably adequate solutions can be architected should sufficient privacy be promised; until then, sensitive information should remain sensibly off-chain, and many things should never be on-chain.
Currently, most privacy solutions cater to extreme users, so they are naturally hobgoblinised and subsequently attract hobgoblins. However, affordances are varied. Eventually, the privacy calculus will shift with the availability of more flexible and ultimately compliant privacy solutions as a reaction to the increasing incursion. In the future, compliant privacy solutions, an internal and external autonomy-preserving middle ground, will bridge the legacy rule of law and Lex Cryptographia. The user will experience a utopia of choice, within reason, regarding their privacy, and the metaverse will (hopefully) be a more fulfilling place to inhabit.